Unified Architecture Design for AI & ML In Digital Products

As someone that has been working in this field for about 12 years, it's very odd to see how the term machine learning has fallen out of fashion for the flashier AI. Though AI has always been quite popular, I do remember a distinctive period before the emergence of LLM when data science, and machine learning were the trendier terms. This came about with the successes of companies like Spotify, Netflix, Uber, Airbnb and their forward thinking product data science organisations whose success relied on progress in recommender systems, predictive analytics ...
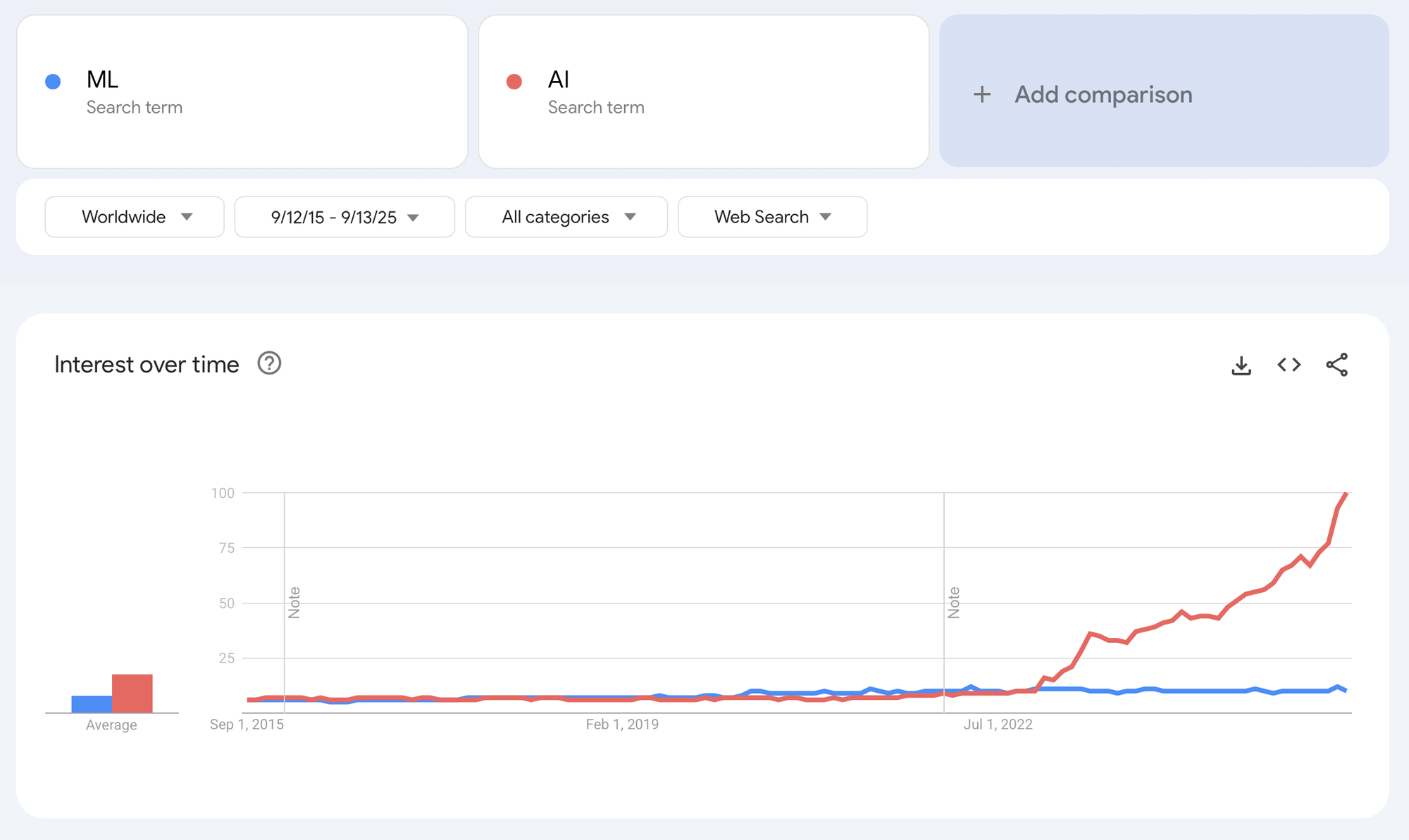
How does AI engineering fit into existing infrastructures? Does AI and ML need to be separate or can both systems be built using a unified platform? In this post I go over a high-level design of a unified architecture that empowers teams to build AI and ML applications.
AI and ML both needs strong data foundations
With the emergence of foundational models, companies are scrambling to take advantage of AI and benefit from all its promises. But AI, just like ML is a data-intensive function. Without solid data foundations, AI projects fail to deliver to the fullest of their potential. Just like, data, data-science and machine learning, only the organisations that are willing to build solid foundations can take full advantage of these technologies.
This can be a challenge because data functions have consistently been undervalued as they are seen as cost functions rather than actual value drivers. this is of course wrong because when done right, data functions are transformative. And you don't need to be a tech giant like Netflix or Spotify to make that happen. The most successful companies that I have had the privilege to work for have had solid data foundations: this is because it signals a leadership that has a long term strategy, and invests in it even if the full benefits are not seen right away. Investing in data is disruptive by nature as it challenges an organisation structure and decision making process.
Data is a socio-technical affair - Barry Smart
What we are experiencing with AI, is not that much different than what has been said over and over again about data science: organisations that are willing to play the long game and invest in the proper foundations are the ones that will take advantage of AI as the transformative technology that it is. As I mentioned in a previous post, generative AI systems for enterprise applications needs company data within the context of their task execution. Just like making data accessible to humans via data analytics, AI requires data via reliable pipelines that is made accessible in a structured manner: for fine tuning, evaluation or prediction.
There are inherent risks of running AI systems without business context or with poor quality data: and that is an operational risk. The magnitude of this risk depends on the application.
Unified Infrastructure
Investing in AI doesn't necessarily means that you need to wait years before getting the benefits of this technology. I do believe that starting off with prototypes, that can deliver value sooner rather than later is the best option to avoid investing resources in an over engineered platform that doesn't suit the actual needs of the organisation. However, when value has been shown and there is executive buy in which usually results in a technical leader being brought on to drive adoption of AI across product features. Thus, building a platform with the appropriate features is paramount. Though AI and ML systems both require data, they make use of it in different ways:
- ML requires data for training, evaluation and prediction
- AI requires data for prompt optimisation, system evaluation and prediction
While ML needs online data for prediction, AI does need data for prompt optimisation but it also requires a context at prediction time: which means that the data needs to be properly indexed. This doesn't necessarily require building two different processes. Both AI and ML applications can be built on top of the same data infrastructure. This unified infrastructure allows to flexibly design features that are available for downstream AI and ML models. How do we define a feature in this framework?
A feature is an individual, measurable property or characteristic of a data point, or a computed property or characteristic of a collection of data points that serves as an input to a model.
AI features may be computed over a collection of data points as this is an efficient way to make available context to a model and still build systems that respond with low enough latency. For instance, a RAG application may use the result of a vector search as a feature to predict the answer to a user's question.
The unified infrastructure proposed is built around the principles of DevOPs, DataOps and MLOPs.
DevOPs
Serving ML and AI applications is usually done via REST API. In its simplest form, applications are ran inside of containerised environments and deployed on orchestration systems such as docker swarm or Kubernetes. At this stage, these applications can be handled just like any backend systems.
Building the infrastructure on the principles of DevOPs is critical. AI / ML systems require solid engineering foundations. I don't go into details about the infrastructure technology selection as the point of this article is to stay high level and discuss needs. These needs can be met by a large number of tools, and the tool selection should be done with business constraints in mind.
Both DataOps and MLOPs are practices that are built using the principles of DevOps but extended to cater to data and models.
DataOPs
Feature stores are the new component that has the capability to power both AI and ML applications. It is the perfect replacement for a semantic layer for organisations that have not yet developed data capabilities. A feature store requires less effort to setup and can remain much more limited in its scope than a semantic layer would be. In the traditional scenario, your feature store would live alongside your semantic layer, however, they can be developed standalone and take some of the responsibilities. A feature store will itself replace the traditional modern data stack in its entirety.
This is a practice I like to call DataOps: data operations that are designed to make high quality data available for both AI and ML. They can be setup quicker than a data platform and their reach is also more limited. This is an approach that works well when building out AI and ML within an organisation that doesn't have a data function. Building a data infrastructure without a data function is going to use precious resources, while attempting to build a data function without leadership buy-in is reckless at best. This is the happy medium: without having to make a case for a data function, building a DataOPs infrastructure is a much more targeted approach that allows to build AI and ML systems.
A feature store will require:
- data ingestion
- data storage
- data transformation
Data ingestion
Data ingestion is a necessity to render business data accessible in a format that is suitable for training, evaluation and prediction. Business data is usually stored in a transactional manner which is not the preferred format for analytics workloads which is what ML requires and to a lesser extent AI.
The introduction of MCP puts into question the need for data ingestion. MCP is an approach to make AI transactional systems rather than analytical one: they are directly connected to source data rather than analytical data. I believe that MCP has some limitations, because it leaves the interpretation of data from multiple sources to the LLM rather than a human which limits how business context and semantic concepts can be integrated into the LLM prediction context. MCP assumes the best case scenario: transactional data is well organised and already has strong semantic design. But this is rarely the case: engineering teams are not designing their databases with this in mind. Data structures evolve over time. Analytic data layers are more stable, but also designed carefully to represent business concepts.
Data storage
There are two types of storage in a feature store:
- offline store: which is similar to a data warehouse, stores business data in its raw form.
- online store: designed for low latency data access and is an extension of the offline store
There are different type of online stores depending on the features needed. The most popular ones are:
- table
- document
- key/value (value can be a vector)
- graph
vector and graph online stores are particular useful for RAG applications. Data engineering is also required to move data from offline to online stores. Data can also be directly ingested into an online store via streaming processing.
Data storage handles both analytical and transactional data structures. Transactional data is indexed for optimal retrieval.
Data transformation
Defined features can be accessed via a feature service. The responsibility of a feature service is to abstract away the retrieval of data from databases but also to store feature definition and the data transformation required to compute a feature.
Data can be retrieved from the feature service for offline or online processing.
MLOPs
In my design, I make no difference between ML and AI. Both applications can be developed using a common platform. The workflow for build AI and ML applications are different however.
- Fine tuning: while this may be controversial I use fine tuning both for ML and AI. I understand this step as an action of the engineer on the system during the experimentation phase to maximise its post fine tuning performance.
- Registration: The final solution can be evaluated and stored into a registry. Registries are critical for reproducibility and audibility of the fine tuning workflow storing all relevant information about the process and the parameters used alongside with the final system evaluation.
Governance
Governance is out of the scope of this post. I will cover this in an upcoming post. But I will give a brief overview: AI and data governance go hand in hand. AI and ML systems are consumers of data, and make decisions based on data, hence a unified governance strategy is the best approach. For instance, the European Union AI act does specify in their assessment data as a potential risk factor. Moreover, high risk AI providers must "conduct data governance".
This is why in this infrastructure overview, governance is all-encompassing.
References





