The Modern Data Platform Design: a tool agnostic approach

The big data echosystem is still too big! There I said it. I still remember seeing this post years ago and as a young and upcoming data scientist and it resonated with me. When I tried to keep up to date with all the advancements in data infrastructure I felt overwhelmed by the breadth of tools, resource to learn about. As I gained experience in the domain, I soon realised that when designing then building or maintaining data platforms, tools matter less than use cases. Use cases are more stable than tools. How do you leverage use cases so that they become generic enough to be useful for design: by developing abstraction layers.
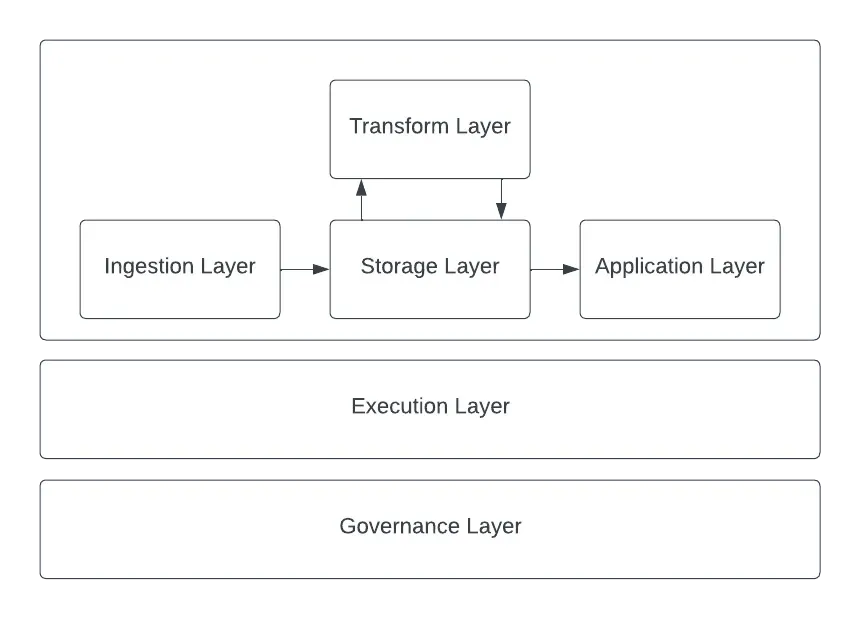
I have been thinking about this for a while, at first my layers were too specific which meant that they were not always reusable. I refined them over time with the learning stemming from building data platforms. I ultimately identified the following:
- ingestion
- storage
- transform
- application
- execution
- governance
Ingestion
The first step towards using data effectively to help a business make decisions is gathering all the data from first, second and third parties into one place. The intelligence in BI is not possible without the learnings possible from joining and analysing data from multiple sources. The ingestion layers covers the tools that make possible the transfer of data from their sources to a centralised storage. Before the widespread use of cloud data integration solutions, this work would be done via ad-hoc scripts and using orchestration tools (usually Airflow + Hadoop / Spark).
As use cases became more and more standardised, cloud solutions have emerged that reduce considerably the engineering effort required to ingest well known data sources (Stitch, Fivetran, AirByte, Segment, …) The emergence of engineering roles focusing on creating usable datasets for analysts has been the most critical additions to data roles in recent years.
Storage
The storage layer is the essential piece of all data platforms. This is the central repository of all data that will ultimately used directly, indirectly (or actually not at all) to help the business answer critical questions and ideally derive actionable insights. The storage layer covers structured (warehouse) or unstructured (lake) data. The maturing in this space has led to the emergence of specific tools such as non-transactional databases optimised for efficiently running complex queries (BigQuery, Snowflake, Redshift).
GCP even provides the ability to query data via SQL directly from storage buckets, which removes the need to ingest data from buckets (data lake) to BigQuery (data warehouse). As a data scientist, interacting with this layer can be very time consuming.
Given the recent evolution of data best practices, if your data analysis and scientists spend too much time interacting with this layer, this means a loss of productivity that compounds over time. The emergence of engineering roles focusing on creating usable datasets for analysts has been the most critical additions to data roles in recent years (sorry machine learning engineers).
Transformation
Raw data can be painful to interact with directly. It’s not suitable for analytics and requires transformation. In legacy system designs, the transform layer would be part of the ingestion layer, which meant that data engineers would create datasets for the whole business to use. Refining them for business cases would be left to analysts and scientists. The issue with this process is that little thought was put into creating the datasets beyond the project requirements.
The lack of reusability meant that a lot of analysts time was spent creating and validating ‘ad-hoc’ datasets and start over again for the next project. Enter Analytics Engineers: skilled SQL coders, they integrate business logic into the data and create generic purpose datasets that reduce the time to insights for analysts and business users. They own and manage the transformation needed to get from raw data to clean datasets.
With a modern transformation layer, managing a data warehouse at scale has become simpler: transformations leverage the database resources: this is the purest form of bringing compute to data. No need to manage or use a Spark cluster. transformations are standardised in pre-defined steps which makes them easier maintained and audited. datasets can be tested for freshness and other conditions, which means that data quality can be consistently monitored. dbt is by far the most popular solution in this space.
However I keep a close eye on Dataform because the potential of an integrated storage and transform layers is an exciting development.
Application
The application layer powers all insights using the transformed datasets provided by Analytics Engineers. What use cases are covered in this layer: business intelligence and visualisation (BI, visualisation, metric store) — popular tools are Looker, Tableau, Superset, … data science (experimentation, interactive development / research) — popular tools are Kubeflow Notebooks, GCP AI Platform Notebooks, Growthbook, … machine learning (prototyping, model management, feature store, prediction at scale) — popular tools are MLFlow, Kubeflow, SageMaker Studio.
I believe that the most exciting advancement in data and analytics in the next few years may come from specific tools being developed for application purposes. For instance, machine learning platforms are in my opinion too focused on production and not enough on the research / experimentation; the integration between these two workflows will be critical for effectively leverage predictive analytics at scale. Metric stores, which are a very recent addition to data stacks, centralise and make business metrics accessible in a way that was not possible before.
Most (if not all) organisations start with BI and visualisation. For this reason, the tools available are more mature than what is currently accessible for data science and machine learning. My advice to data (platform) engineers is to get more familiar with data science and machine learning workflow requirements even if you do not support these functions (yet).
Allowing data scientists and machine learning engineers to access compute and tools adapted to their needs can make a noticeable difference in the development cycle speed of their end-products.
Execution
This layer is becoming less and less prevalent in modern data platforms. Legacy systems would heavily rely on ad-hoc executions. These executions would require to be ran periodically, thus execution layers require two components: scheduler / orchestrator (Airflow, Luigi) resource allocator / manager (Spark, Hadoop) Managing an execution layer used to require very specific knowledge. If you have ever tried to setup your own Hadoop or Spark cluster you know how painful these system can be to manage. With the emergence of managed solution for resources management (AWS EMR, or GCP DataProc) and orchestration (GCP Cloud Composer), most of the barriers have been removed.
As we started to better understand use cases, specific tools emerged providing solutions that encapsulate (partially or completely) the management of resources across the data stack: ingestion: Stitch, Fivetran storage: BigQuery, Snowflake transform: dbt, dataform application: looker, AI Platform.
This means that it is nowadays almost possible to design entirely managed data platform! As data engineering workflows become more and more standardised, execution layers have started focused on workflows that are less predictable. The burgeoning of machine learning platforms are a perfect example of this trend. Execution layers provide flexibility and ultimately can still be a powerful layers in any data platforms.
Cloud solutions can offer their own execution but for some tools (such as dbt) it’s always possible to self-manage the execution. This will, of course, require more engineering efforts. The tradeoff is more control over the computing resources and execution environments.
Governance
This is the new kid in town. As organisations invest more and more in data, all of the previous layers need to be scalable. With growing regulatory environment around privacy and data use, a few problems arise: security / regulation compliance: how do we comply with data privacy regulations while making access to the data secure as the number of end-users grow? discoverability: how do end users can easily find data products? reliability: how do we monitor the datasets and tools health to make sure that we catch issues early?
Security has historically been managed via the data warehouse access control. However with new data privacy guidelines, transform tools also allow to encode specific tables / columns which allows to have a fine-grain access control (all still powered by the data warehouse access control, but easier managed via the transform tool). Monitoring tools have emerged in recent years, allowing to test data against complex conditions. Transform tools allow to run basic tests (which are important) however, data reliability may required more complex tools. Monte-Carlo or Great Expectations are two good examples of data quality monitoring tools. Discoverability is easiest to tackle, as it only requires to collect information from the storage and transform layer and expose them to help make the discovery of data products easier. This becomes necessary at scale.
Effective governance with one tool is hard, because it requires a third party application to connect to multiple parts of your system to collect and gather the relevant informations and in more advanced systems, manage access control in a centralised fashion. The platform that seem closest to fulfill all these needs is Atlan. The space is growing at a fast pace, this there are also some interesting alternatives both proprietary (Datafold) or open-source (DataHub).
Final Words
As we gain more understanding of how to best leverage data for analytics uses, (from trials and errors) new roles emerge (analytics engineering, machine learning ops engineering) or role are refined / expanded (data engineering) Data engineers have grown from managing data pipelines and providing the data for the whole organisation to use to providing the infrastructure as well as the data so that other functions (analytics engineering and analysts) can build data products for the whole organisation to use.
This has resulted in data engineers focusing more on the engineering challenges of data analytics. This is an exciting development, because it highlights that we understand better what scalable analytics infrastructure should look like and that the labour division has improved. This means that the scope of work downstream becomes better defined as a result and ultimately less turnover in the future as better defined role vary less from one organisation to another.
Note: Initially published on medium: https://airejie.medium.com/the-modern-data-platform-design-a-tool-agnostic-approach-250ebe4a0a5


